TL;DR. I ran a classic visual search experiment (feature versus conjunction) on vision-language models and lined them up against roughly 80,000 human trials, using each model's reasoning tokens as a stand-in for reaction time. The models reproduce the human fingerprint: feature search is flat, while conjunction effort climbs with the number of items. Frontier models (Claude Opus 4.8, GPT-5.5) stay accurate where weaker ones collapsed, and a blur control shows that the conjunction effort is genuine search rather than trouble reading small letters. The one un-human quirk: the models spend more effort confirming a target that is present than ruling out one that is absent, the reverse of how people search.
Spend enough time studying human vision and you develop a certain instinct - when a new system claims to "see", you want to run it through the experiments we have spent fifty years running on people. I spent a decade modeling how humans search a cluttered scene for a target. So when vision-language models started describing and creating images fluently, I had an obvious question. Do they search the images the way we do, or do they just look like they do?
There is a clean way to ask. Visual search is one of the most studied tasks in cognitive psychology, and it has a famous signature.
Two kinds of search
Look for the red T in each display below. On the left, every other letter is a black T, so the red one seems to jump out at you no matter how many distractors there are. On the right, the distractors are red Ls and black Ts. Now color alone will not find it (the Ls are red too) and shape alone will not find it (the other Ts are T-shaped too). You have to check items more or less one at a time.
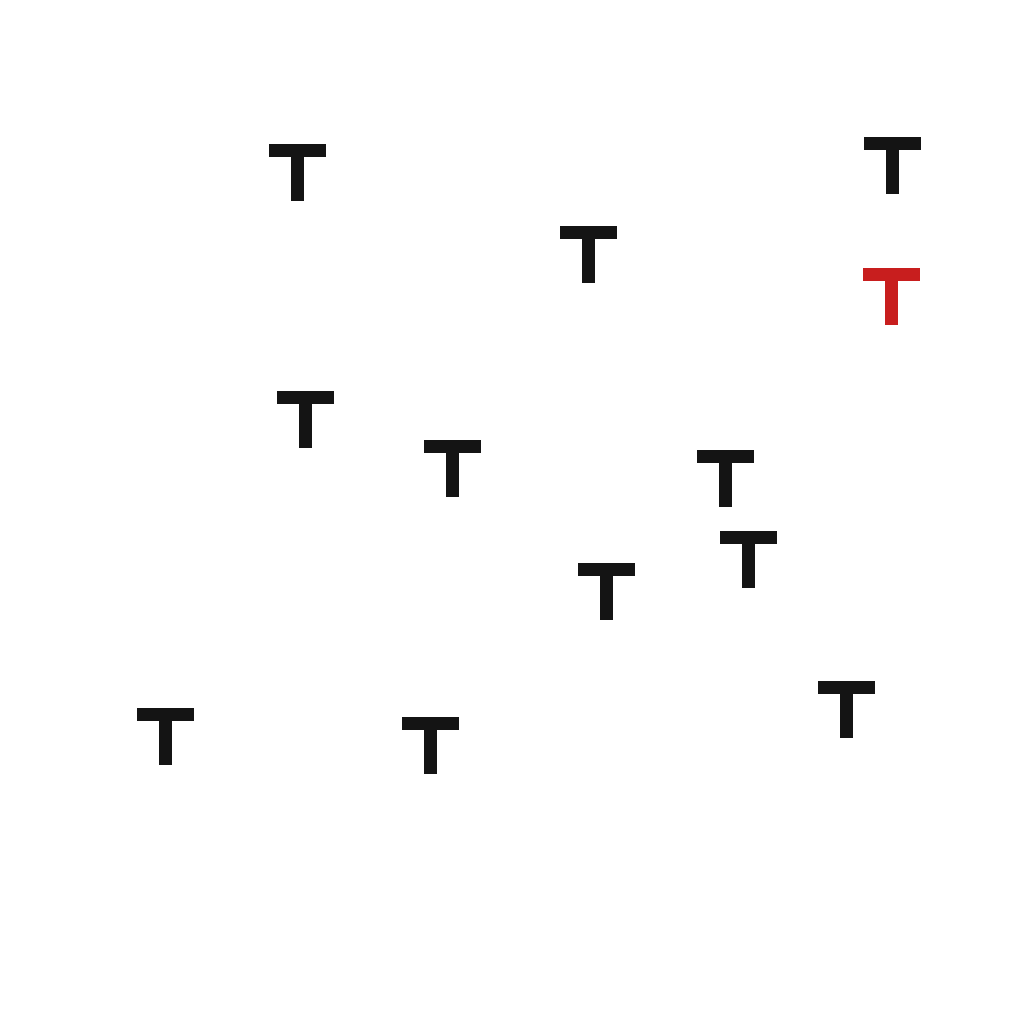
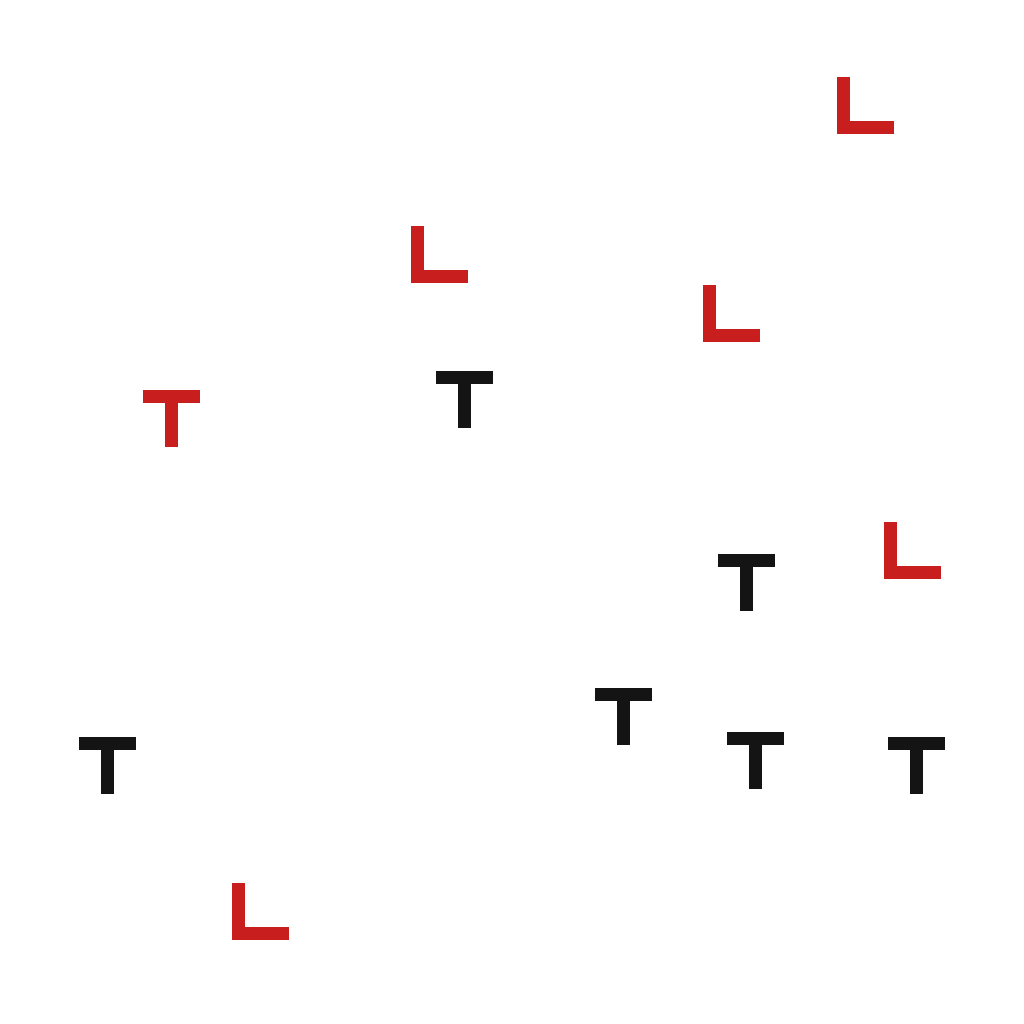
The signature, going back to Treisman and Gelade (1980), is in how reaction time scales with the number of items. Feature search is flat: finding the pop-out target takes about the same time whether there are four items or forty. Conjunction search is not flat: each extra distractor adds time, because you are binding two features together and checking candidates one by one. Flat versus sloped is the fingerprint of two different mechanisms.
Running the experiment on machines
I built 400 search displays, crossing two conditions (feature, conjunction) with four set sizes (4, 8, 16, 32 items), half containing a target. Then I showed each one to four models and asked a single question. The exact call sent the image plus one line of text: "Look at this image carefully. Is there a red letter T in this image? Answer with exactly one word: yes or no." I tested Claude and GPT-4o in their standard mode, and two reasoning models (Claude with extended thinking, and OpenAI's o4-mini) that deliberate before answering.
In standard mode the model sees the image and answers almost immediately. There is no space to reason; whatever the model can extract in a single forward pass through the network is what you get. This is the closest machine analog to brief-presentation visual search in humans, where you flash a display too quickly for the eyes to move and scan item by item. The reasoning models, by contrast, get to think first: they generate a private chain of reasoning before committing to yes or no, which is the machine version of taking your time on a hard search.
Reaction time does not exist for a single model call, so I needed an analog. For the reasoning models I used the number of thinking tokens the model spent per trial. If a model is doing anything like serial search, it should spend more effort on conjunction trials as the display grows, and stay flat on feature trials. That is the machine version of an RT slope.
First result: accuracy
Start with whether the models even get the answer right, and put the humans alongside them. The first thing to notice is that people are not the interesting line here: human accuracy sits near 98% for both feature and conjunction search at every set size. That is because in the original experiments the display stayed on screen until the person responded, so they could take as long as they needed. Humans pay for a hard search in time, not in errors.
The models have no such luxury in a single answer. Every model is perfect on feature search at every set size: the green line sits at 100% and never moves. Conjunction search is a different story. As the display grows, accuracy falls, and how far it falls is its own little ranking of the models.
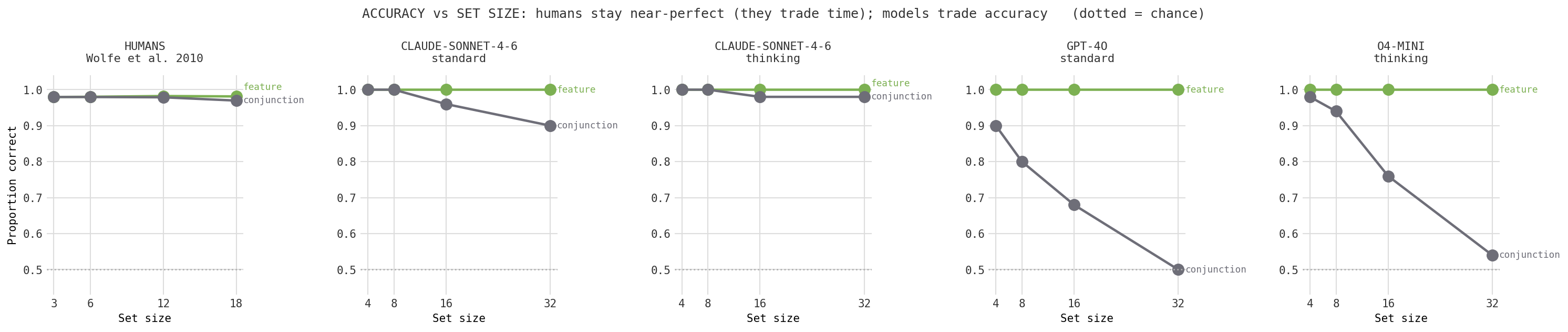
Claude in standard mode slips only a little, from 100% down to 90% at 32 items. With extended thinking it barely slips at all, holding 98% even on the hardest displays. GPT-4o, by contrast, collapses all the way to chance at 32 items: it has essentially stopped searching and is just answering "no." Across every model, almost all of the errors are misses rather than false alarms, which is itself human-like. People too tend to quit and say "not there" rather than hallucinate a target.
Second result: effort
Accuracy tells you whether the model can do the task. Effort tells you how. Here is human reaction time next to model reasoning effort. The shape is what matters. Green is feature search, gray is conjunction; filled markers are target-present trials, open markers target-absent.
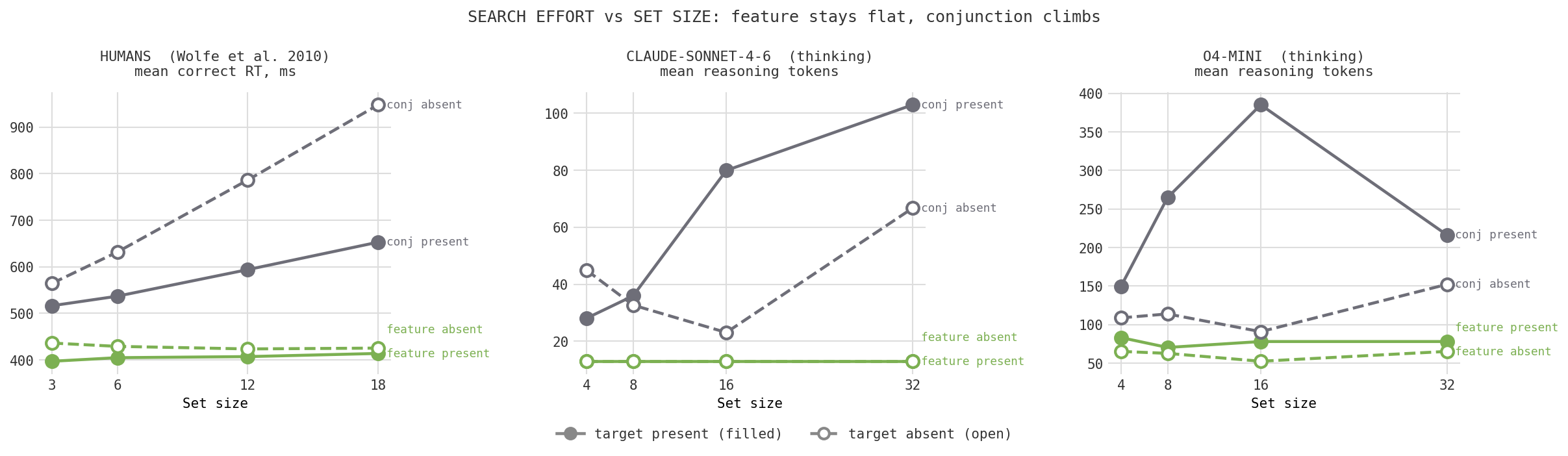
The models reproduce the human signature. Claude with extended thinking spends a flat ~13 tokens on feature search regardless of set size, and climbs from about 36 to 85 tokens on conjunction search as the display grows. Nobody told it to work harder on the binding task at larger set sizes. It allocated effort the way human reaction time does, on its own. That extra effort is what buys back the accuracy in Figure 2.
Where machines and people part ways
One difference is too clean to ignore. In humans, the target-absent slope is steeper than the target-present slope, by roughly two to one. That is the classic signature of exhaustive search: to be sure something is not there, you have to check everything, which takes longer than stumbling onto a target that is present.
Claude shows the opposite. Its target-present trials cost more reasoning tokens than its target-absent trials. The model seems to spend its effort confirming and localizing a target it has found, rather than exhaustively verifying an absence. Whatever it is doing when it says "no," it is not the patient, item-by-item sweep that people do. With only 25 trials per cell this is suggestive rather than settled, but it is exactly the kind of crack that tells you a system is reaching a human-like output through a non-human process.
o4-mini shows a third pattern worth flagging: its effort rises through the middle set sizes and then drops at the largest one, while its accuracy falls toward chance. That looks less like searching and more like giving up, as if the display had outrun what it could handle. Whether that ceiling is about perception or something else is a question I come back to later.
Do the newest models still do this?
The runs above used mid-tier models. A fair worry is that the failures, especially GPT-4o collapsing to chance, just reflect weak models rather than anything about how machines search. So I repeated the thinking experiment on the current flagships: Claude Opus 4.8 and GPT-5.5.
Two things change and one thing stays. What changes first is accuracy. The frontier models do not degrade: both stay essentially perfect on conjunction search at every set size, 98 to 100% even at 32 items, where GPT-4o had fallen to chance. The accuracy collapse really was a capability limit, and it is gone. What also changes is that, like humans, these models now hold accuracy steady and pay for difficulty in effort instead of errors.
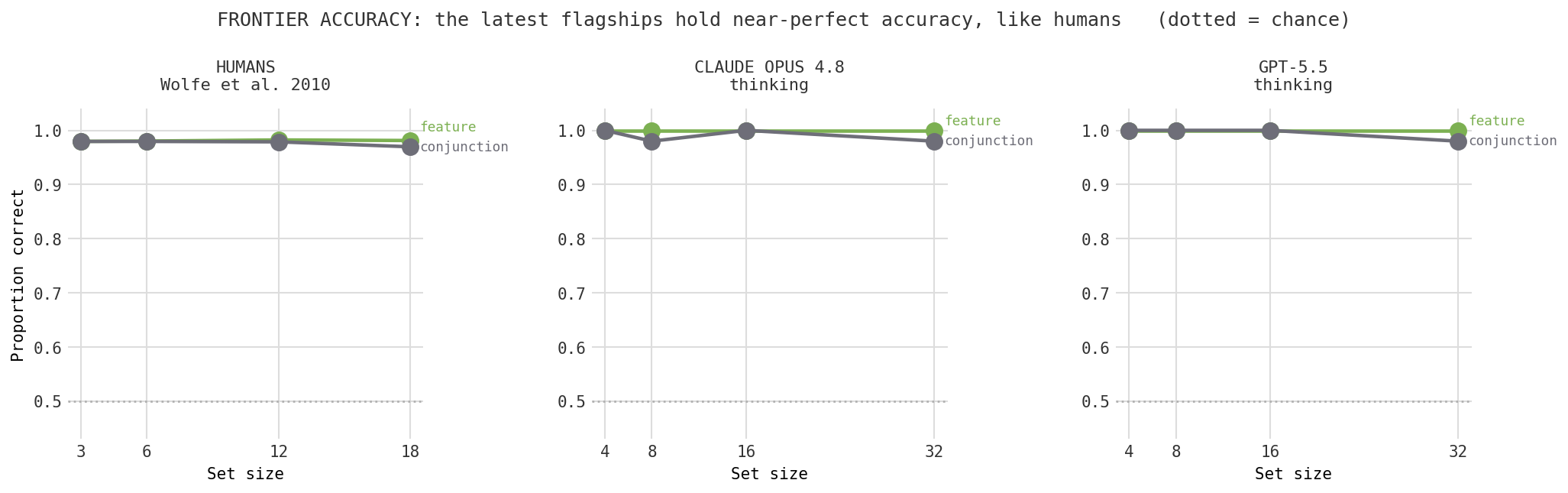
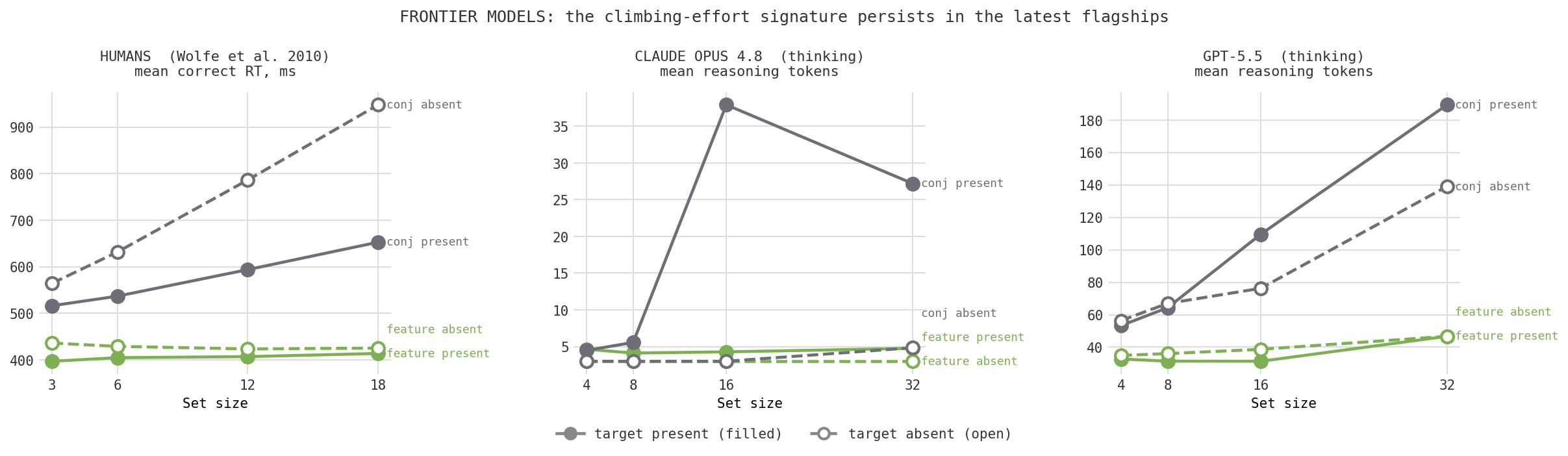
What stays is the signature itself. Both flagships keep feature search flat and let conjunction effort climb with set size, and GPT-5.5 produces the cleanest, most monotonic effort slope of any model I tested, a near textbook match to the shape of the human reaction-time curve. The target-present-costs-more reversal from earlier also survives into the newest models, so that particular departure from human search is not a quirk of one model generation but looks robust. Better models did not erase the fingerprint; they sharpened it.
Was the effort really about searching?
Here is a worry that nagged at me. When a model spends more tokens on a crowded conjunction display, is it really doing more searching, or is it just straining to make out small letters? Telling a T from an L comes down to a few pixels, so maybe some of that effort was the cost of squinting, not the cost of binding color to shape. There is a clean way to separate the two: hold everything fixed and degrade only how sharply the letters can be resolved. If the effort was about resolving shapes, blurrier letters should cost more (or break accuracy). If it was genuine search, detail should not matter until the letters become truly unreadable.
So I took the exact high-clutter layouts (set sizes 16 and 32, both feature and conjunction) and made reduced-detail copies: I shrank each image down and blew it back up to the original size, which strips out fine detail while keeping the frame, the layout, and the image size identical. The letters get progressively blurrier from "crisp" (the original) down to a smear only a few pixels across. Because the image size never changes, the model's encoder treats every version the same way; only the resolvable detail moves. Feature search rides along as a control: its target pops out by color, and color survives blurring far better than the fine strokes that tell a T from an L, so feature effort should barely move.
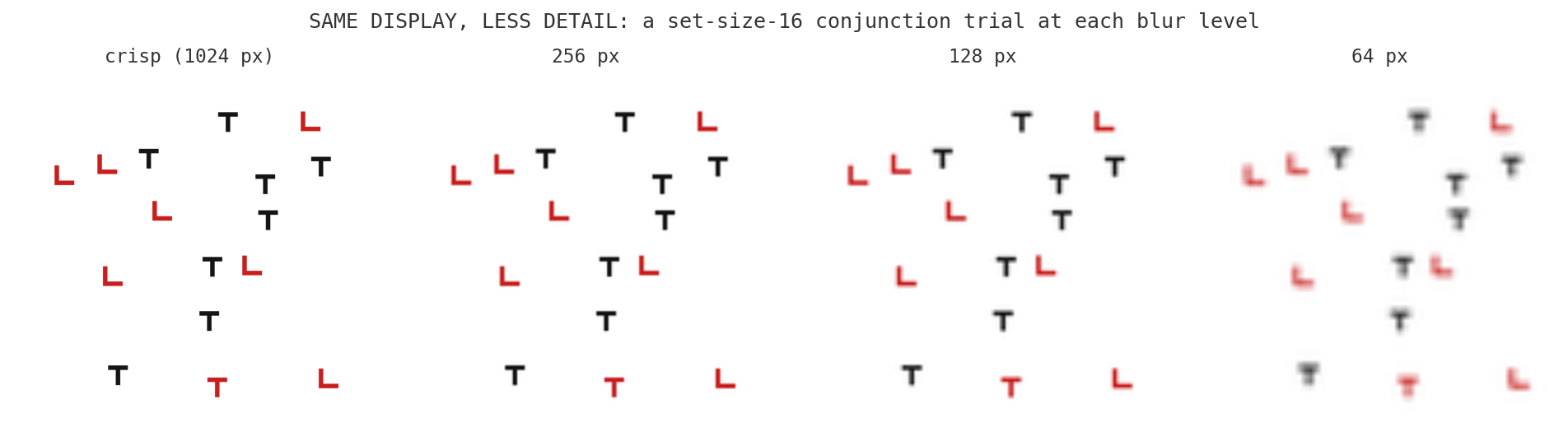
Start with accuracy. It never breaks. Even when the letters are reduced to a few-pixel smear, both models still find the red T at every set size, in both conditions. Whatever limits these models, it is not the ability to resolve a blurry letter.
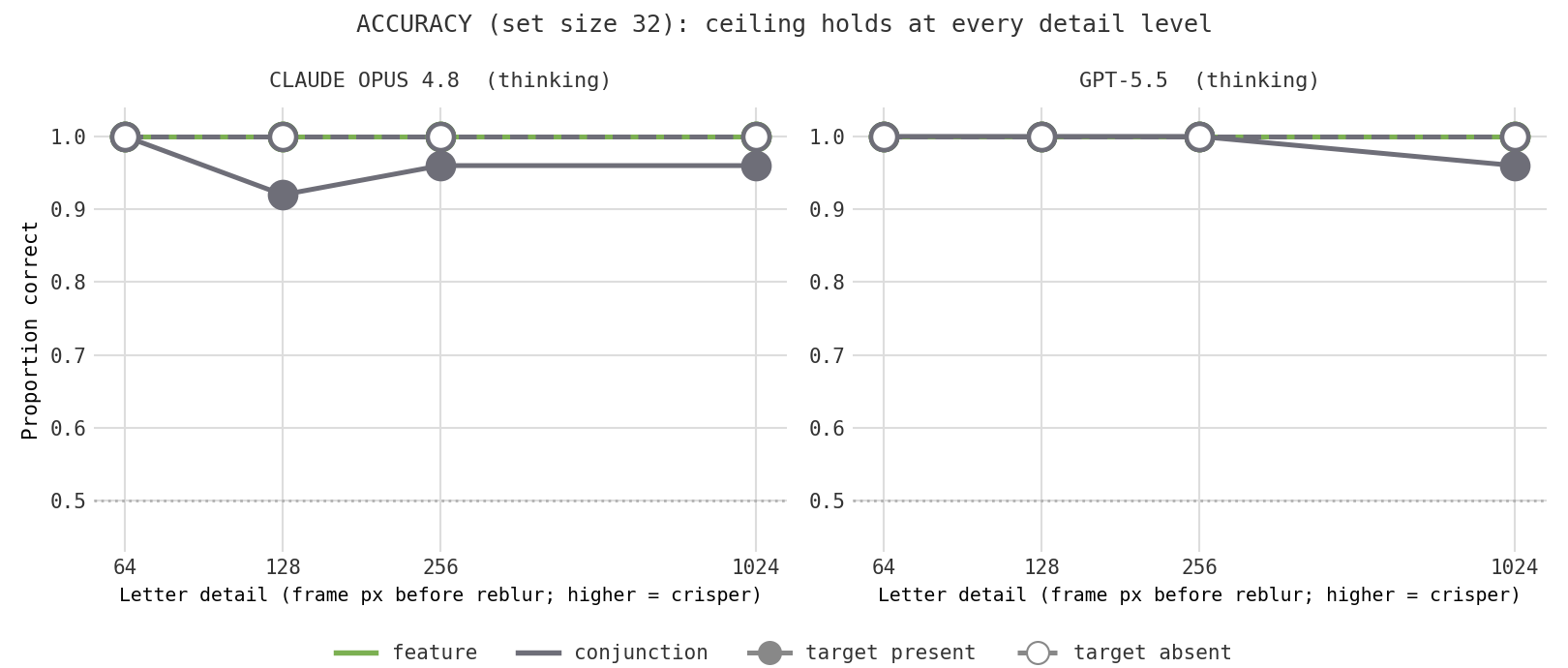
Effort is where the conditions part. The control behaves exactly as it should, which is what makes the rest trustworthy: feature search effort (the green lines) stays flat along the floor no matter how badly I blur the image, because finding a red thing does not depend on fine detail. So blur is not simply making the models think more in general. It is specifically conjunction, the task that needs you to resolve shape, that pays a price when detail is stripped away.
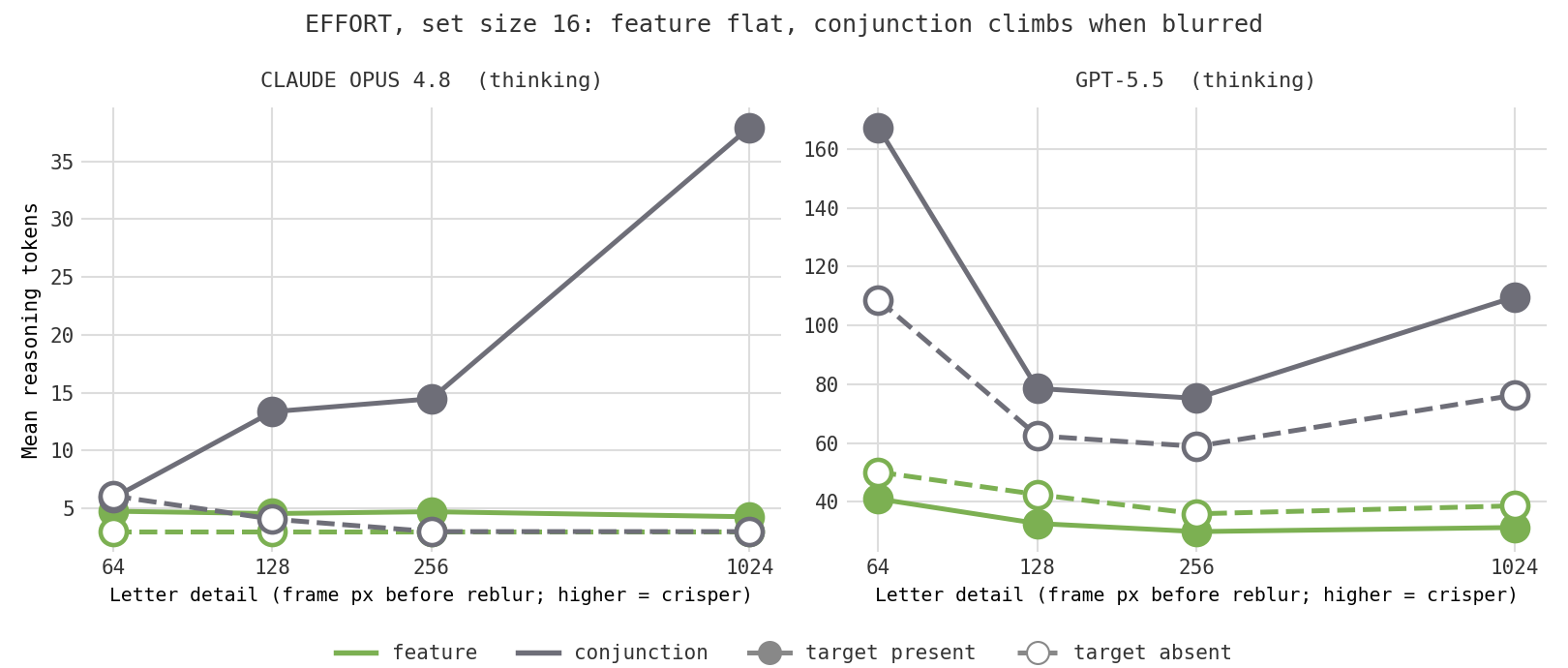
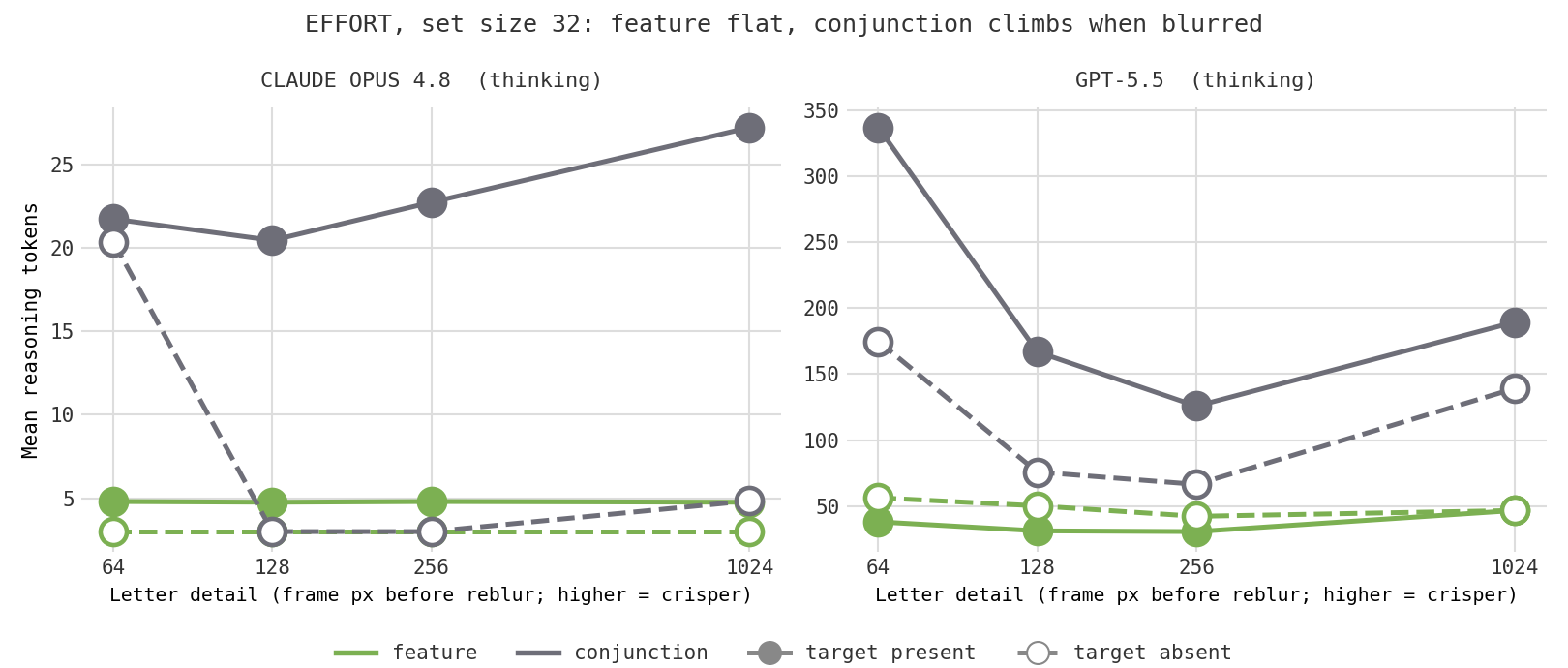
For GPT-5.5 the conjunction tokens trace a rough U: they are lowest at medium detail, and they climb at the blurriest end, where the most crowded displays cost the most effort of anything in the whole study. So there is a real perceptual component, but it only shows up when the image is badly degraded, and the model spends that extra effort to keep its accuracy rather than giving up. Crucially, the crisp baseline is not the cheap end of the curve: the original, easy-to-read letters cost as much or more effort than the mildly blurred ones. That is the key point. The effort the models put into a normal conjunction display is not mainly the cost of squinting. It looks like genuine search, with a perceptual surcharge that appears only at the extreme.
Claude Opus spends so few tokens to begin with (often under twenty) that its curve is near the floor and noisy; the blurriest case nudges it up too, but I would not lean on it further. And the usual caveat holds: 25 trials per cell, so these are suggestive shapes, not precise measurements.
Why I find this interesting
The behaviorism here is the point. We cannot open up these models and read off a "search mechanism," any more than we can for a person. But we can do what psychophysics has always done: design the right stimuli, measure the right behavior, and let the shape of the data constrain what the underlying process could be. The tools I used to study human attention turn out to be a surprisingly sharp probe for machine cognition, and the places where the analogy breaks are more informative than the places where it holds.
Code, stimuli, and analysis are on request. The human benchmark comes from the Wolfe lab's public datasets (Wolfe et al., 2010; Palmer et al., 2011), used with the kind of deep, small-n design that this literature is built on.